简介
企业智能知识库细颗粒度权限管理保障知识安全权限管理模块基于 RBAC(基于角色的访问控制)模型,并结合 ABAC(基于属性的访问控制)技术进行深化设计。在工程企业中,根据员工的岗位角色,如项目经理、技术负责人、普通施工人员等,分配不同的基础权限。同时,结合文档的密级属性、项目所属部门等因素,进一步细化权限。授予特定高层管理人员查看与修改权限,普通员工即使身处项目团队,也无法访问。通过这种多层次、多维度的权限控制,确保企业知识资产在流转与使用过程中的安全性与合规性。企业智能知识库知识来源可追溯,答案可靠。南通京源企业智能知识库

京源企业智能知识库,行业价值图谱:从效率提升到战略赋能的跨越在环保工程企业,企业智能知识库成为项目管理。投标团队可快速检索过往类似项目的技术方案与成本核算数据,将标书编制周期从 15 天压缩至 5 天;现场运维人员通过移动终端接入系统,实时查询设备维修手册与故障处理案例,使平均故障修复时间(MTTR)缩短至 4 小时以内。对于集团型企业,设备的分布式部署能力可实现总部与分支机构的知识实时同步。总部制定的技术标准、管理规范能即时推送至各子公司,而实践中产生的创新经验也能快速反哺至总部知识库,形成 “上下联动” 的知识迭代机制。某省级环保集团应用该设备后,内部知识共享效率提升 3 倍,年度培训成本降低 40%。南通中小型企业 企业智能知识库企业智能知识库生成专业化答案,提升获取效率。
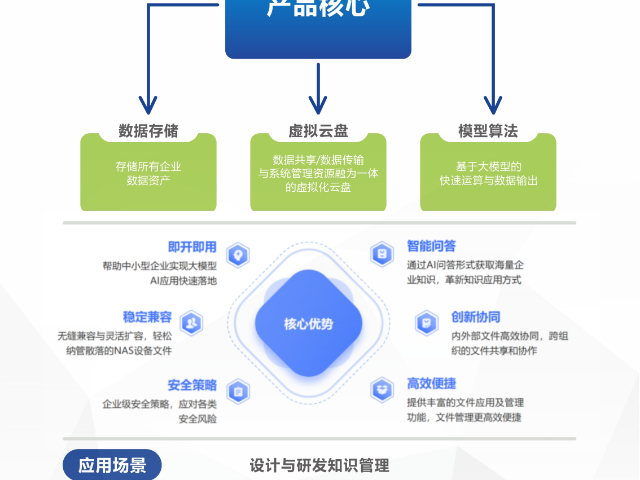
京源・太乙企业智能知识库之所以能在建筑、工程、科技研发等行业发挥强大作用,源于其精妙且先进的技术架构,该架构融合了当下前沿技术,从硬件基础到软件算法,企业知识管理与应用赋能。强劲算力支撑京源・太乙企业智能知识库搭载了先进的计算芯片,采用制程工艺,具备强大的并行计算能力。以高性能 CPU 与 GPU 协同工作为基础,针对大模型运算进行了深度优化。在处理建筑行业复杂的结构力学计算时,CPU 凭借其多、高频率的特性,高效执行逻辑控制与通用计算任务;GPU 则凭借其大规模并行计算单元,快速完成矩阵运算、图形渲染等**度数值计算,大幅缩短设计方案的模拟验证时间。在某超高层商业综合体结构设计中,运用该一体机进行风荷载模拟计算,相较于传统服务器,运算速度提升了 4 倍,原本需要数小时的计算任务,如今能在短时间内完成,为设计方案的快速迭代提供有力支持。
京源企业智能知识库提升知识检索效率的路径解析在企业知识管理场景中,京源环保企业智能知识库通过技术架构创新与流程重构,构建起从知识采集到智能应用的全链路效率提升体系,实现知识检索从 “大海捞针” 到 “精细匹配” 的质变。全维度知识预处理:消除检索障碍设备的知识管理系统首先解决 “知识碎片化” 问题。针对企业中 80% 以上的非结构化数据,系统通过三重处理机制完成结构化转化:采用 OCR 图文识别技术处理扫描版图纸、报告,字符识别准确率达 99.2%;运用自然语言处理技术解析音视频会议记录,将语音内容转化为带时间戳的文本摘要;通过版式分析算法识别 PDF 文档中的表格、公式,保留原始排版逻辑的同时实现数据字段提取。对于环保行业特有的技术文档,系统内置专业处理引擎。例如在解析污水处理工艺流程图时,能自动识别设备符号、管道走向、参数标注等关键信息,构建包含 “设备型号 - 工艺参数 - 运行条件” 的关联数据库。这种专业化预处理使后续检索时的信息提取效率提升 3 倍以上,避免用户在大量无效信息中筛选关键内容。企业智能知识库追溯至具体文档,章节段落清晰。

京源企业智能知识库,海量存储体系设备内置企业级大容量存储模块,采用高速 NVMe SSD 固态硬盘与高容量机械硬盘混合存储架构。NVMe SSD 用于存储企业高频访问的技术文档、设计图纸以及数据库索引等,能实现微秒级的数据读写响应,保障大模型检索与知识调用的即时性。对于海量的历史项目资料、专利文献备份等低频访问数据,则存储于大容量机械硬盘中,在保证数据安全性的同时,实现存储成本的有效控制。像工程企业积累的长达数十年的项目施工记录、竣工文档等,都能在该存储体系中妥善保存,且随时可按需快速调取。企业智能知识库员工快速查项目经验,借鉴便捷。南通企业智能知识库批发价
企业智能知识库科技研发领域,管理专利资料。南通京源企业智能知识库
京源企业智能知识库,有智能交互引擎:大模型 + RAG 技术重构知识应用场景京源环保企业智能知识库的核心竞争力在于将大模型能力与检索增强生成(RAG)技术深度融合,打造出具备行业认知的智能系统。设备内置针对环保行业训练的专属大模型,通过千亿级参数规模构建起专业领域的知识图谱,涵盖水处理工艺、废气治理技术、环保设备运维等 2000 余个细分知识点。RAG 技术的应用实现了知识检索从 “关键词匹配” 到 “语义理解” 的跨越。当用户提出问题时,系统首先通过向量数据库将自然语言转化为高维向量,在企业知识库中进行相似度匹配,精细定位相关知识片段后,再交由大模型进行逻辑整合与自然语言生成。这种 “检索 - 增强 - 生成” 的闭环机制,使答案既保证了知识的准确性,又具备符合人类表达习惯的流畅性。南通京源企业智能知识库